 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoMIC: Collaborative Memory and Insights Circulation for Long-Horizon LLM Agents in Cloud-Edge Systems
May 30, 2026Deploying lightweight Large Language Model (LLM) agents on edge servers can reduce latency and move agentic services closer to users, but resource-constrained edge models often struggle with long-horizon tasks that require persistent memory, subgoal tracking, and reflection. Fine-tuning edge models after deployment is costly and difficult to scale across heterogeneous nodes, while purely local memory leaves agents with isolated experience and growing prompt context. We propose \textsc{CoMIC}, a parameter-update-free cloud-edge framework for Collaborative Memory and Insights Circulation. \textsc{CoMIC} follows a \textit{Centralized Reflection, Decentralized Execution} design: edge agents execute locally using subgoal-oriented hierarchical memory and selective re-expansion of relevant histories, while a cloud-side LLM critic asynchronously evaluates completed trajectories, filters reusable experience, and aggregates cross-agent guidance keyed by semantic subgoal identifiers. Across five long-horizon agent tasks spanning symbolic planning and text interaction, \textsc{CoMIC} improves progress rate and action grounding for weak edge agents and yields task-dependent success-rate gains without updating model parameters.
PRISM: Generation-Time Detection and Mitigation of Secret Leakage in Multi-Agent LLM Pipelines
May 11, 2026Multi-agent LLM systems introduce a security risk in which sensitive information accessed by one agent can propagate through shared context and reappear in downstream outputs, even without explicit adversarial intent. We formalise this phenomenon as propagation amplification, where leakage risk increases across agent boundaries as sensitive content is repeatedly exposed to downstream generators. Existing defences, including prompt-based safeguards, static pattern matching, and LLM-as-judge filtering, are not designed for this setting: they either operate after generation, rely primarily on surface-form patterns, or add substantial latency without modelling the generation process itself. To resolve these issues, we propose PRISM, a real-time defence that treats credential leakage as a sequential risk accumulation problem during generation. At each decoding step, PRISM combines 16 signals spanning lexical, structural, information-theoretic, behavioural, and contextual features into a calibrated risk score, enabling per-token intervention through green, yellow, and red risk zones. Our central observation is that credential reproduction is often preceded by a measurable shift in generation dynamics, characterised by entropy collapse and increasing logit concentration. When combined with text-structural cues such as identifier-pattern detection, these temporal signals provide an early warning of leakage before a secret is fully reconstructed. Across a 2,000-task adversarial benchmark covering 13 attack categories and three pressure levels in a heterogeneous four-agent pipeline, PRISM achieves F1 = 0.832 with precision = 1.000 and recall = 0.712, while producing no observed leakage on our benchmark (0.0% task-level leak rate) and preserving output utility of 0.893. It substantially outperforms the strongest baseline, Span Tagger, which achieves F1 = 0.719 with a 15.0% task-level leak rate.
SBOMs into Agentic AIBOMs: Schema Extensions, Agentic Orchestration, and Reproducibility Evaluation
Mar 09, 2026Software supply-chain security requires provenance mechanisms that support reproducibility and vulnerability assessment under dynamic execution conditions. Conventional Software Bills of Materials (SBOMs) provide static dependency inventories but cannot capture runtime behaviour, environment drift, or exploitability context. This paper introduces agentic Artificial Intelligence Bills of Materials (AIBOMs), extending SBOMs into active provenance artefacts through autonomous, policy-constrained reasoning. We present an agentic AIBOM framework based on a multi-agent architecture comprising (i) a baseline environment reconstruction agent (MCP), (ii) a runtime dependency and drift-monitoring agent (A2A), and (iii) a policy-aware vulnerability and VEX reasoning agent (AGNTCY). These agents generate contextual exploitability assertions by combining runtime execution evidence, dependency usage, and environmental mitigations with ISO/IEC 20153:2025 Common Security Advisory Framework (CSAF) v2.0 semantics. Exploitability is expressed via structured VEX assertions rather than enforcement actions. The framework introduces minimal, standards-aligned schema extensions to CycloneDX and SPDX, capturing execution context, dependency evolution, and agent decision provenance while preserving interoperability. Evaluation across heterogeneous analytical workloads demonstrates improved runtime dependency capture, reproducibility fidelity, and stability of vulnerability interpretation compared with established provenance systems, with low computational overhead. Ablation studies confirm that each agent contributes distinct capabilities unavailable through deterministic automation.
DriveSafe: A Hierarchical Risk Taxonomy for Safety-Critical LLM-Based Driving Assistants
Jan 17, 2026Large Language Models (LLMs) are increasingly integrated into vehicle-based digital assistants, where unsafe, ambiguous, or legally incorrect responses can lead to serious safety, ethical, and regulatory consequences. Despite growing interest in LLM safety, existing taxonomies and evaluation frameworks remain largely general-purpose and fail to capture the domain-specific risks inherent to real-world driving scenarios. In this paper, we introduce DriveSafe, a hierarchical, four-level risk taxonomy designed to systematically characterize safety-critical failure modes of LLM-based driving assistants. The taxonomy comprises 129 fine-grained atomic risk categories spanning technical, legal, societal, and ethical dimensions, grounded in real-world driving regulations and safety principles and reviewed by domain experts. To validate the safety relevance and realism of the constructed prompts, we evaluate their refusal behavior across six widely deployed LLMs. Our analysis shows that the evaluated models often fail to appropriately refuse unsafe or non-compliant driving-related queries, underscoring the limitations of general-purpose safety alignment in driving contexts.
Private Federated Multiclass Post-hoc Calibration
Oct 02, 2025

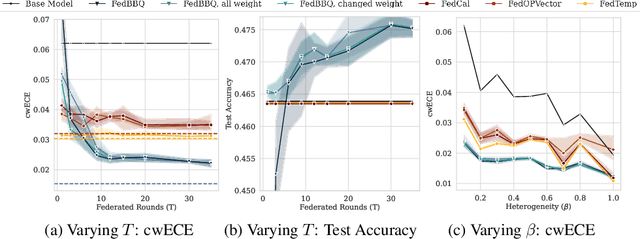

Calibrating machine learning models so that predicted probabilities better reflect the true outcome frequencies is crucial for reliable decision-making across many applications. In Federated Learning (FL), the goal is to train a global model on data which is distributed across multiple clients and cannot be centralized due to privacy concerns. FL is applied in key areas such as healthcare and finance where calibration is strongly required, yet federated private calibration has been largely overlooked. This work introduces the integration of post-hoc model calibration techniques within FL. Specifically, we transfer traditional centralized calibration methods such as histogram binning and temperature scaling into federated environments and define new methods to operate them under strong client heterogeneity. We study (1) a federated setting and (2) a user-level Differential Privacy (DP) setting and demonstrate how both federation and DP impacts calibration accuracy. We propose strategies to mitigate degradation commonly observed under heterogeneity and our findings highlight that our federated temperature scaling works best for DP-FL whereas our weighted binning approach is best when DP is not required.
Individualised Counterfactual Examples Using Conformal Prediction Intervals
May 28, 2025



Counterfactual explanations for black-box models aim to pr ovide insight into an algorithmic decision to its recipient. For a binary classification problem an individual counterfactual details which features might be changed for the model to infer the opposite class. High-dimensional feature spaces that are typical of machine learning classification models admit many possible counterfactual examples to a decision, and so it is important to identify additional criteria to select the most useful counterfactuals. In this paper, we explore the idea that the counterfactuals should be maximally informative when considering the knowledge of a specific individual about the underlying classifier. To quantify this information gain we explicitly model the knowledge of the individual, and assess the uncertainty of predictions which the individual makes by the width of a conformal prediction interval. Regions of feature space where the prediction interval is wide correspond to areas where the confidence in decision making is low, and an additional counterfactual example might be more informative to an individual. To explore and evaluate our individualised conformal prediction interval counterfactuals (CPICFs), first we present a synthetic data set on a hypercube which allows us to fully visualise the decision boundary, conformal intervals via three different methods, and resultant CPICFs. Second, in this synthetic data set we explore the impact of a single CPICF on the knowledge of an individual locally around the original query. Finally, in both our synthetic data set and a complex real world dataset with a combination of continuous and discrete variables, we measure the utility of these counterfactuals via data augmentation, testing the performance on a held out set.
Justified Evidence Collection for Argument-based AI Fairness Assurance
May 12, 2025It is well recognised that ensuring fair AI systems is a complex sociotechnical challenge, which requires careful deliberation and continuous oversight across all stages of a system's lifecycle, from defining requirements to model deployment and deprovisioning. Dynamic argument-based assurance cases, which present structured arguments supported by evidence, have emerged as a systematic approach to evaluating and mitigating safety risks and hazards in AI-enabled system development and have also been extended to deal with broader normative goals such as fairness and explainability. This paper introduces a systems-engineering-driven framework, supported by software tooling, to operationalise a dynamic approach to argument-based assurance in two stages. In the first stage, during the requirements planning phase, a multi-disciplinary and multi-stakeholder team define goals and claims to be established (and evidenced) by conducting a comprehensive fairness governance process. In the second stage, a continuous monitoring interface gathers evidence from existing artefacts (e.g. metrics from automated tests), such as model, data, and use case documentation, to support these arguments dynamically. The framework's effectiveness is demonstrated through an illustrative case study in finance, with a focus on supporting fairness-related arguments.
Representation Engineering for Large-Language Models: Survey and Research Challenges
Feb 24, 2025



Large-language models are capable of completing a variety of tasks, but remain unpredictable and intractable. Representation engineering seeks to resolve this problem through a new approach utilizing samples of contrasting inputs to detect and edit high-level representations of concepts such as honesty, harmfulness or power-seeking. We formalize the goals and methods of representation engineering to present a cohesive picture of work in this emerging discipline. We compare it with alternative approaches, such as mechanistic interpretability, prompt-engineering and fine-tuning. We outline risks such as performance decrease, compute time increases and steerability issues. We present a clear agenda for future research to build predictable, dynamic, safe and personalizable LLMs.
Distributed, communication-efficient, and differentially private estimation of KL divergence
Nov 25, 2024



A key task in managing distributed, sensitive data is to measure the extent to which a distribution changes. Understanding this drift can effectively support a variety of federated learning and analytics tasks. However, in many practical settings sharing such information can be undesirable (e.g., for privacy concerns) or infeasible (e.g., for high communication costs). In this work, we describe novel algorithmic approaches for estimating the KL divergence of data across federated models of computation, under differential privacy. We analyze their theoretical properties and present an empirical study of their performance. We explore parameter settings that optimize the accuracy of the algorithm catering to each of the settings; these provide sub-variations that are applicable to real-world tasks, addressing different context- and application-specific trust level requirements. Our experimental results confirm that our private estimators achieve accuracy comparable to a baseline algorithm without differential privacy guarantees.
Towards Robust Federated Analytics via Differentially Private Measurements of Statistical Heterogeneity
Nov 07, 2024



Statistical heterogeneity is a measure of how skewed the samples of a dataset are. It is a common problem in the study of differential privacy that the usage of a statistically heterogeneous dataset results in a significant loss of accuracy. In federated scenarios, statistical heterogeneity is more likely to happen, and so the above problem is even more pressing. We explore the three most promising ways to measure statistical heterogeneity and give formulae for their accuracy, while simultaneously incorporating differential privacy. We find the optimum privacy parameters via an analytic mechanism, which incorporates root finding methods. We validate the main theorems and related hypotheses experimentally, and test the robustness of the analytic mechanism to different heterogeneity levels. The analytic mechanism in a distributed setting delivers superior accuracy to all combinations involving the classic mechanism and/or the centralized setting. All measures of statistical heterogeneity do not lose significant accuracy when a heterogeneous sample is used.